1. 이클립스에서 HTML 문서 작업하기
[HTML 만들기] 만들고 싶은 위치의 폴더 선택 > 우클릭 > New > File 클릭
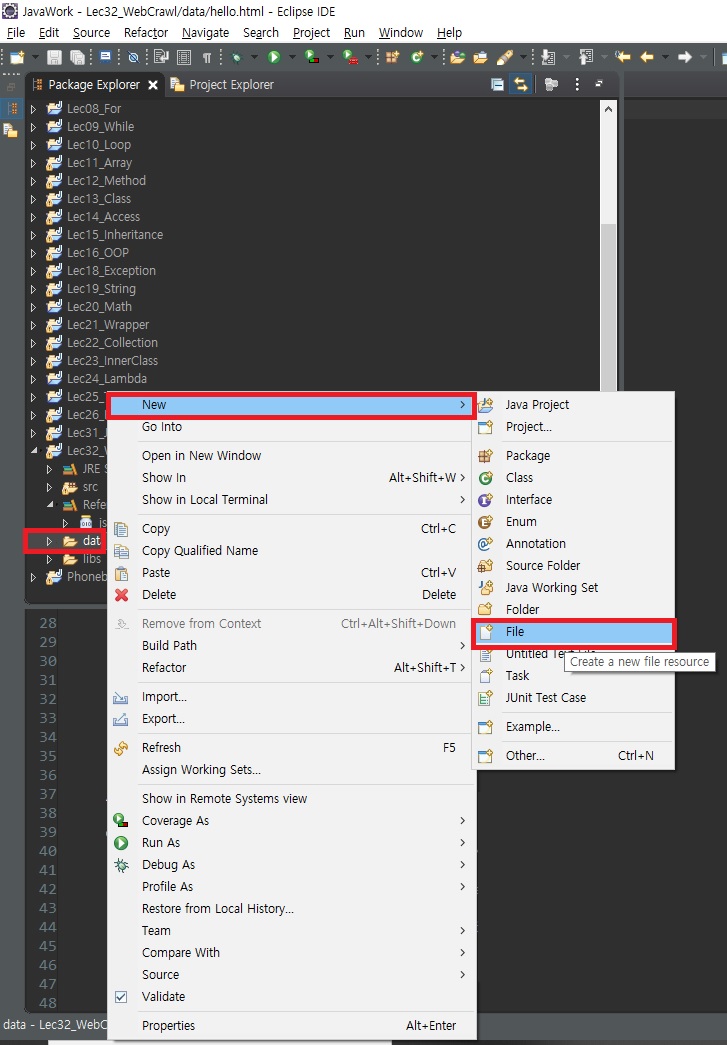
> File name에 원하는 파일명 작성 > Finish 클릭
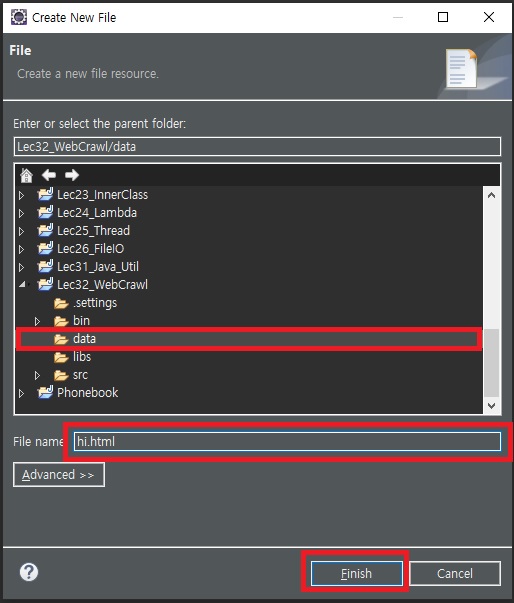
> 아래 사진과 같이 되었다면 파일 잘 만들어짐, 작성하면 됨
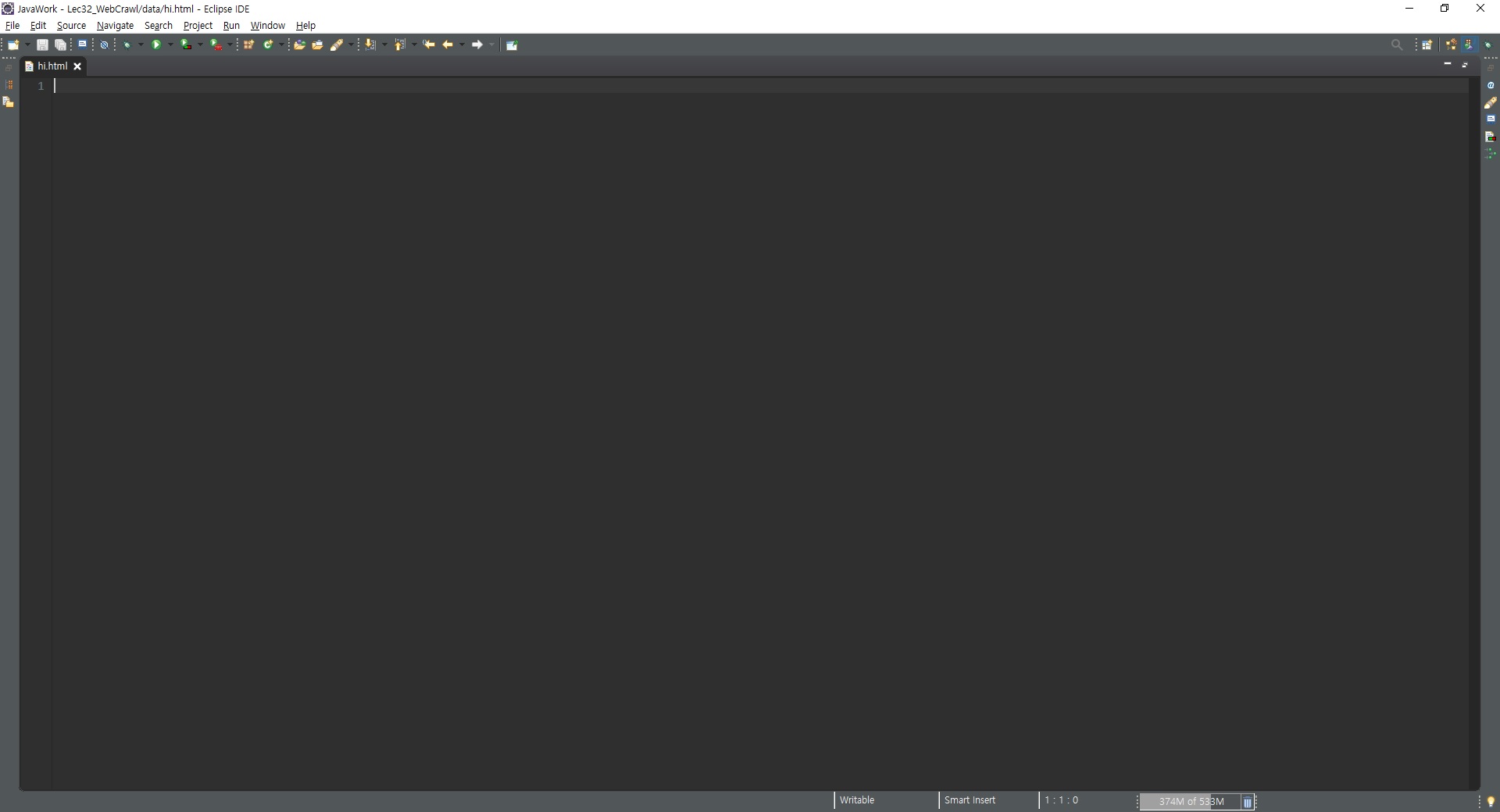
[브라우저로 확인하기] Open With > Web Browser 클릭

** 아래의 사진처럼 코드 작성하면서 브라우저로 결과값 확인 가능 **

2. MIME 타입
https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/MIME_types
3. 자바스크립트는 인터프리터이다.
4. 자바스크립트는 세미콜론 써도 되고 안써도 된다.
5. 자바스크립트 변수 선언은 타입을 선언하지 않으며 수시로 타입 변경이 가능
6. json 이쁘게 보는 View 다운로드 받는법(기본 제공되는 View는 보기 힘들다)
: chrome 웹 스토어 > jsonview 검색 > Chrome에 추가 클릭

[실습코드]
1. Lec32_WebCrawl
1) com.lec.java.crawl00 패키지, Crawl00Main 클래스
** Lec_WebCrawl 프로젝트 안에 data 폴더 만들고 hello.html 문서 만들기
<!DOCTYPE heml>
<html>
<head>
<meta charset="utf-8">
<title>hello html</title>
<style>
/* CSS 주석입니다. */
div.article span:nth-child(2){
background : Aqua;
}
</style>
</head>
<!-- 이것이 html 주석이다, 블럭 주석 -->
<body>
안녕하세요, 저는 샤인입니다
<div id="header">
<h1>제목1 입니다</h1>
<p>문단 1입니다</p>
<p>문단 2입니다</p>
<p>문단 3입니다</p>
<p>문단 4입니다</p>
</div>
<div>
<h2>제목2 입니다</h2>
<div class="navi">
<span>[aaa]</span>
<span>[bbb]</span>
<span>[ccc]</span>
</div>
<div id="addr">
<ul class="favorite">
<li><a href="https://www.naver.com">네이버</a></li>
<li><a href="https://www.daum.net">Daum</a></li>
<li><a href="https://www.nate.com">NATE</a></li>
</ul>
</div>
</div>
<div class="article">
<img src="https://i.ytimg.com/vi/EdKwiK2DWw0/hqdefault.jpg"
width="500px" height="500px">
<img src="https://post-phinf.pstatic.net/MjAxOTA3MjNfMTQy/MDAxNTYzODY5Mjc1NTEx.OkONORSQvUEoXBh26HRIllEndsdYbKzN7spNHq8sh7Qg.qEgruGasP0TuDUj6eXG1XyHEBJoDjmLzvI9QkMLkp68g.JPEG/00.jpg?type=w1200"
width="500px" height="500px">
<img src="https://cdn.clien.net/web/api/file/F01/8539742/1b2ef8a271aedc.jpeg?w=780&h=30000"
width="500px" height="500px">
</div>
</body>
</html>
** Crawl00Main 클래스
package com.lec.java.crawl00;
import java.io.File;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Crawl00Main {
public static void main(String[] args) throws IOException {
System.out.println("Jsoup");
Element element;
Elements elements;
File f = new File("data/hello.html");
Document doc = Jsoup.parse(f, "UTF-8"); // 파일 -> Document 변환 (DOM구조 변환)
//System.out.println(doc.outerHtml());
element = doc.selectFirst("div");
//System.out.println(element.outerHtml());
elements = doc.select("div");
//System.out.println(elements.size());
// Elements 의 get(n) -> n번째 Element 리턴
element = elements.get(3);
//System.out.println(element.outerHtml());
// Elements 모두 출력하기
// for(int i = 0; i < elements.size(); i++) {
// element = elements.get(i);
// System.out.println(element.outerHtml());
// System.out.println();
// }
// for문보다는 Enhanced for문을 주로 더 많이 사용함
// for(Element e : elements) {
// System.out.println(e.outerHtml());
// System.out.println();
// }
element = doc.selectFirst("div#addr");
//System.out.println(element.outerHtml());
elements = element.select("ul.favorite a");
//System.out.println(elements.size() + "개");
// for(Element e : elements) {
// //System.out.println(e.outerHtml());
// System.out.println(e.text().trim());
// System.out.println(e.attr("href").trim());
// }
// TODO
// 이미지에 있는 소스 url 뽑아 보기
element = doc.selectFirst("div.article");
//System.out.println(element.outerHtml());
elements = element.select("div.article img");
//System.out.println(elements.size() + "개");
System.out.println();
for(Element img : doc.select("img")) {
//System.out.println(img.outerHtml());
System.out.println(img.attr("src").trim());
}
System.out.println("\n프로그램 종료");
} // end main()
} // end class
2) com.lec.java.crawl02 패키지, Crawl02Main 클래스
package com.lec.java.crawl02;
import org.jsoup.Jsoup;
import java.io.IOException;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Crawl02Main {
public static void main(String[] args) throws IOException {
System.out.println("네이트 인기 검색어");
// TODO
// https://www.nate.com/
String url;
Response response;
Document doc;
Element element;
url = "https://www.nate.com/";
response = Jsoup.connect(url).execute();
// 접속 성공, request 결과 코드 200 출력 완..!!
System.out.println(response.statusCode());
doc = response.parse();
Elements search_elements = doc.select(".search_keyword dd a");
System.out.println(search_elements.size() + "개");
for(Element e : search_elements) {
System.out.println(e.text().trim());
}
System.out.println();
for(Element e : search_elements) {
System.out.println(e.attr("href").trim());
}
System.out.println("\n프로그램 종료");
}
}
3) com.lec.java.crawl03 패키지, Crawl03Main 클래스
package com.lec.java.crawl03;
import java.io.IOException;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Crawl03Main {
public static void main(String[] args) throws IOException {
System.out.println("Daum 실시간 검색어");
// TODO
// http://www.daum.net
// 15개
String url;
Response response;
Document doc;
Element element;
url = "http://www.daum.net";
response = Jsoup.connect(url).execute();
// 접속 성공, request 결과 코드 200 출력 완..!!
System.out.println(response.statusCode());
doc = response.parse();
Elements favor_elements = doc.select("div.slide_favorsch ul.list_favorsch li a");
System.out.println(favor_elements.size() + " 개");
for(Element e : favor_elements) {
System.out.println(e.text().trim());
System.out.println(e.attr("href").trim());
}
System.out.println("\n프로그램 종료");
}
}
4) com.lec.java.url 패키지, UrlMain 클래스
package com.lec.java.url;
import java.net.MalformedURLException;
import java.net.URL;
/*
* URL (Uniform Resource Locator) 객체
* java.net.URL 객체를 통해 인터넷 관련 리소스 접근.
*
* URL 객체의 메소드를 통해 URL을 분해해볼수 있다.
*
* 가령 : https://aaa.bbb.com:88/abc/def/zzz.ddd?name=uu&age=12 의 경우
* getProtocol(): https
* getHost(): aaa.bbb.com
* getPath(): /abc/def/zzz.ddd
* getPort(): 88
* getFile(): /abc/def/zzz.ddd?name=uu&age=12
* getQuery(): name=uu&age=12
*
* 단, 파일 이름의 경우 따로 추출해야 하는 번거로움 있다.
*
* URI (Uniform Resource Identifier) 는 URL 의 상위 개념
*/
public class UrlMain {
public static void main(String[] args) {
System.out.println("URL 객체");
String[] urls = new String[] {
"https://aaa.bbb.com:88/abc/def/zzz.ddd?name=uu&age=12",
"http://www.example.com/some/path/to/a/file.xml?foo=bar#test",
"hhh://asdf",
"ftp://asdf",
"http://",
"aaa.bb.com"
};
for (int i = 0; i < urls.length; i++) {
System.out.println(urls[i]);
URL url = null;
try {
url = new URL(urls[i]);
} catch (MalformedURLException e) {
System.out.println("\t잘못된 URL 입니다!\t" + e.getMessage());
continue;
}
System.out.println("\tgetProtocol(): " + url.getProtocol());
System.out.println("\tgetHost(): " + url.getHost());
System.out.println("\tgetPath(): " + url.getPath());
System.out.println("\tgetPort(): " + url.getPort());
System.out.println("\tgetFile(): " + url.getFile());
System.out.println("\tgetQuery(): " + url.getQuery());
// 파일명, 확장자
if(url.getPath().length() > 0) {
String filename = url.getPath().substring(url.getPath().lastIndexOf('/') + 1);
String fileBaseName=filename.substring(0, filename.lastIndexOf('.'));
String fileExt = filename.substring(filename.lastIndexOf('.') + 1);
System.out.println("\t파일명 : " + filename);
System.out.println("\t파일base명 : " + fileBaseName);
System.out.println("\t파일확장자 : " + fileExt);
}
} // end for
} // end main()
} // end class
5) com.lec.java.urlencode 패키지, UrlEncodeMain 클래스
package com.lec.java.urlencode;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.net.URLEncoder;
/*
* URLEncoder, URLDecoder
*
* URL 은 한글, 특수기호, 공백등의 문자를 담을수 없다.
* 따라서 위와 같은 문자를 URL에 담으려면 URL 인코딩 을 하여야 한다.
*
* O : https://search.naver.com/search.naver?sm=top_hty&fbm=1&ie=utf8&query=%ED%8C%8C%EC%9D%B4%EC%8D%AC
* X : https://search.naver.com/search.naver?sm=top_hty&fbm=1&ie=utf8&query=파이썬
*
* 인코딩-디코딩 온라인 테스트 사이트
* http://coderstoolbox.net/string/#!encoding=xml&action=encode&charset=us_ascii
*
*/
public class UrlEncodeMain {
public static void main(String[] args) {
System.out.println("URLEncoder, URLDecoder");
String str = "파이썬";
// 한글관련 자주 사용되는 인코딩
String charset[] = {
"euc-kr", "ksc5601", "cp949", "ms949", // 한글 표현 -> 2byte
"iso-8859-1", "8859_1", "ascii", // 한글 불가
"UTF-8", // 한글표현 -> 3byte
};
for (int i = 0; i < charset.length; i++) {
try {
// 문자열 -> URL 인코딩
System.out.printf("%11s -> %s\n", charset[i],
URLEncoder.encode(str, charset[i]));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
System.out.println();
String enc_utf8 = "%ED%8C%8C%EC%9D%B4%EC%8D%AC";
try {
System.out.println(URLDecoder.decode(enc_utf8, "UTF-8"));
System.out.println(URLDecoder.decode(enc_utf8, "euc-kr"));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
} // end main()
} // end class
6) com.lec.java.crawl04 패키지, Crawl04Main 클래스
package com.lec.java.crawl04;
import java.io.IOException;
import java.net.URLEncoder;
import java.util.Scanner;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Crawl04Main {
public static void main(String[] args) throws IOException {
System.out.println("네이버 연관 검색어");
String url;
Document doc;
Response response;
Elements elements;
String searchKeyword;
Scanner sc = new Scanner(System.in);
System.out.print("검색어를 입력하세요 : ");
searchKeyword = sc.nextLine();
sc.close();
// 네이버 검색페이지는 utf-8로 url encode 함
String encoded = URLEncoder.encode(searchKeyword, "utf-8");
url = "https://search.naver.com/search.naver?sm=top_sug.pre&fbm=1&acr=3&acq=wkqk&qdt=0&ie=utf8&query=" + encoded;
System.out.println(url); // 생성된 url 확인해보자!
doc = Jsoup.connect(url).execute().parse();
// TODO
// 연관검색어 출력하기
elements = doc.select(".lst_relate ul li");
System.out.println("총 " + elements.size() + "개");
for(Element element : elements) {
System.out.println(element.selectFirst("a").text());
}
System.out.println("\n프로그램 종료");
}
}
7) com.lec.java.crawl05 패키지, Crawl05Main, InfoBook 클래스
** Crawl05Main 클래스
package com.lec.java.crawl05;
import java.io.IOException;
import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.Scanner;
import org.jsoup.Jsoup;
import org.jsoup.Connection.Response;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/*
* '검색어' 입력받아서
* 첫페이지의 '국내도서' 첫페이지 20개 아이템 크롤링
* 책이름 / 책가격 / 상세페이지 url / 썸네일 url
*
* yes24.com 검색페이지는 euc-kr 로 URL 인코딩 되어 있다.
* 한글 1글자당 2byte 인코딩
*
*/
public class Crawl05Main {
public static void main(String[] args) throws IOException {
System.out.println("yes24.com 검색결과 페이지");
Scanner sc = new Scanner(System.in);
System.out.print("검색어를 입력하세요 : ");
String search = sc.nextLine();
sc.close();
Crawl05Main app = new Crawl05Main();
ArrayList<InfoBook> list = app.crawlYes24(search);
for(InfoBook e : list) {
System.out.println(e);
}
System.out.println("\n프로그램 종료");
} // end main()
private ArrayList<InfoBook> crawlYes24(String search) throws IOException {
ArrayList<InfoBook> list = new ArrayList<InfoBook>();
String url;
Document doc;
Response response;
Element elements;
Elements rowElements;
// selector
// #schMid_wrap > div:nth-child(3)
url = "http://www.yes24.com/searchcorner/Search?keywordAd=&keyword=&domain=ALL&qdomain=%C0%FC%C3%BC&Wcode=001_005&query=" + URLEncoder.encode(search, "euc-kr");
System.out.println(url); // 확인용
doc = Jsoup.connect(url).execute().parse();
rowElements = doc.select("#schMid_wrap > div.goods_list_wrap.mgt30").get(0).select("tr:nth-child(odd)");
System.out.println(rowElements.size() + " 개"); // 확인용
for(Element e : rowElements) {
String imgUrl = e.selectFirst("td.goods_img > a > img").attr("src").trim();
//System.out.println(imgUrl); // 확인용
Element infoElement = e.selectFirst("td.goods_infogrp > p.goods_name > a");
String bookTitle = infoElement.text().trim();
String linkUrl = "http://www.yes24.com" + infoElement.attr("href").trim();
//System.out.println(bookTitle + " : " + linkUrl); // 확인용
double price = Double.parseDouble(
e.selectFirst("td.goods_infogrp > div.goods_price > em.yes_b").text().trim().replace(",", ""));
//System.out.println(price + "원"); // 확인용
list.add(new InfoBook(bookTitle, price, linkUrl, imgUrl));
}
return list;
}
} // end class
** InfoBook 클래스
package com.lec.java.crawl05;
public class InfoBook {
private String bookTitle; // 책제목
private double price; // 책가격
private String url; // 상세페이지 url
private String imgUrl; // 썸네일 url
// 기본생성자
public InfoBook() {}
// 매개변수 생성자
public InfoBook(String bookTitle, double price, String url, String imgUrl) {
super();
this.bookTitle = bookTitle;
this.price = price;
this.url = url;
this.imgUrl = imgUrl;
}
// getter&setter
public String getBookTitle() {return bookTitle;}
public void setBookTitle(String bookTitle) {this.bookTitle = bookTitle;}
public double getPrice() {return price;}
public void setPrice(double price) {this.price = price;}
public String getUrl() {return url;}
public void setUrl(String url) {this.url = url;}
public String getImgUrl() {return imgUrl;}
public void setImgUrl(String imgUrl) {this.imgUrl = imgUrl;}
@Override
public String toString() {
return bookTitle + ":" + price + "원, URL: " + url + ", img: " + imgUrl;
}
}
8) com.lec.java.crawl06 패키지, Crawl06Main 클래스
package com.lec.java.crawl06;
import java.awt.image.BufferedImage;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLDecoder;
import javax.imageio.ImageIO;
/*
* 웹에서 이미지와 같은 바이너리 형태 리소스 다운로드 받기
*
* 방법1 : URL의 openStream() → InputStream
* 방법2 : HttpURLConnection의 getInputStream() → InputStream
* 방법3 : ImageIO 객체 사용 : 이미지객체
*
* <프로젝트에 download 폴더 만들고 진행하세요>
*
* 예제에 사용한 미디어 출처
* https://www.w3schools.com/html/html5_video.asp
* https://www.w3schools.com/html/html5_audio.asp
* https://www.w3schools.com/howto/howto_css_fullscreen_video.asp
*
* 예제에 사용한 이미지 출처
* https://www.w3schools.com/css/css_image_gallery.asp
*
* 예제에 사용한 데이터 출처
* 공공데이터 포털 - 파일데이터
* https://www.data.go.kr/search/index.do?index=DATA&query=¤tPage=1&countPerPage=10&sortType=VIEW_COUNT
*/
public class Crawl06Main {
public static final String FILEPATH = "download";
public static void main(String[] args) throws IOException {
System.out.println("웹 리소스 다운로드");
Crawl06Main app = new Crawl06Main();
String [] movUrls = {
"https://www.w3schools.com/html/movie.mp4", // 영상
"https://www.w3schools.com/howto/rain.mp4",
"https://www.w3schools.com/html/mov_bbb.mp4",
"https://www.w3schools.com/html/horse.ogg" // 음성
};
// 데이터. URL 에 파일명이 없는 형태
String [] dataUrls = {
"https://www.data.go.kr/dataset/fileDownload.do?atchFileId=FILE_000000001524257&fileDetailSn=1&publicDataDetailPk=uddi:af2e59b7-9f3a-4624-94ae-9ac9d785b62b", // https://www.data.go.kr/dataset/15007122/fileData.do 건강검진정보
"https://www.data.go.kr/dataset/fileDownload.do?atchFileId=FILE_000000001562989&fileDetailSn=1&publicDataDetailPk=uddi:e9317e2f-fb83-43c8-914e-85ac6cca6736_201909101530", // https://www.data.go.kr/dataset/3038489/fileData.do 교통사고통계
"https://www.data.go.kr/dataset/fileDownload.do?atchFileId=FILE_000000001585803&fileDetailSn=1&publicDataDetailPk=uddi:7a68a482-4e3f-4cf8-851a-d4857fa2bff7" // https://www.data.go.kr/dataset/3041272/fileData.do 전국산업단지현황통계
};
// 이미지, jpg
String [] imgUrls = {
"https://www.w3schools.com/css/img_5terre.jpg",
"https://www.w3schools.com/css/img_forest.jpg",
"https://www.w3schools.com/css/img_lights.jpg",
"https://www.w3schools.com/css/img_mountains.jpg"
};
// System.out.println();
// for (int i = 0; i < movUrls.length; i++) {app.download1(movUrls[i]);}
// System.out.println();
// for (int i = 0; i < dataUrls.length; i++) {app.download2(movUrls[i]);}
System.out.println();
for (int i = 0; i < imgUrls.length; i++) {app.download3(imgUrls[i]);}
System.out.println("\n프로그램 종료");
} // end main()
// 방법1
// URL 의 openStream()
// 단순히 byte 스트림으로만 입력 가능
// 파일 이름, 타입등 의 정보는 알 수 없다.
public void download1(String srcUrl) throws IOException {
URL url = null;
InputStream in = null;
OutputStream out = null;
BufferedOutputStream bout = null;
BufferedInputStream bin = null;
String dstFile = null; // 저장할 파일 이름
url = new URL(srcUrl);
in = url.openStream(); // URL -> InputStream, 매우 중요한 문장..!!
dstFile = fileNameFromURL(url);
out = new FileOutputStream(FILEPATH + File.separator + dstFile); // 저장할 파일 경로
bin = new BufferedInputStream(in);
bout = new BufferedOutputStream(out);
while(true) {
int data = bin.read();
if(data == -1) {break;}
bout.write(data);
}
bin.close();
bout.close();
System.out.println("다운로드: " + srcUrl + " → " + dstFile);
} // end download1()
// 방법2
// HttpURLConnection 객체 사용
// HttpURLConnection 의 getInputStream()
// 장점: 파일사이즈, 타입, 이름 등을 미리 알수 있다.
public void download2(String srcUrl) throws IOException {
URL url = null;
HttpURLConnection conn = null;
InputStream in = null;
BufferedInputStream bin = null;
FileOutputStream out = null;
BufferedOutputStream bout = null;
String dstFile = null;
url = new URL(srcUrl);
conn = (HttpURLConnection)url.openConnection();
int contentLength = conn.getContentLength(); // 파일크기
String contentType = conn.getContentType(); // 파일종류 MIME-TYPE 확인가능
// https://developer.mozilla.org/ko/docs/Web/HTTP/Basics_of_HTTP/MIME_types
// 다운로드 받는 파일 이름 확인 가능
String raw = conn.getHeaderField("Content-Disposition");
if(raw != null && raw.indexOf("=") != -1) {
String fileName = raw.split("=")[1].trim();
dstFile = URLDecoder.decode(fileName, "UTF-8");
}
in = conn.getInputStream(); // InputStream <- HttpURLConnection
bin = new BufferedInputStream(in);
out = new FileOutputStream(FILEPATH + File.separator + dstFile);
bout = new BufferedOutputStream(out);
byte[] buf = new byte[contentLength];
int byteImg;
while((byteImg = bin.read(buf)) != -1) {
bout.write(buf, 0, byteImg);
}
bout.close();
bin.close();
System.out.println("다운로드: " + srcUrl + "\n\t → " + dstFile);
System.out.println("\t" + contentLength + " bytes " + contentType);
} // end download2()
// 방법3
// ImageIO 객체 사용
public void download3(String srcUrl) throws IOException {
String dstFile = null;
URL url = new URL(srcUrl);
dstFile = fileNameFromURL(url);
BufferedImage imgData = ImageIO.read(url);
File file = new File(FILEPATH + File.separator + dstFile);
ImageIO.write(imgData, "jpg", file);
System.out.println("다운로드: " + srcUrl + " → " + dstFile);
System.out.println("\t" + imgData.getWidth() + " x " + imgData.getHeight());
} // end download3()
// url 에서 파일명 추출
public String fileNameFromURL(URL url) {
return url.getPath().substring(url.getPath().lastIndexOf('/') + 1);
}
} // end class
[추가] URL의 openStream() -> InputStream

[추가] HttpURLConnection의 getInputStream() -> InputStream

[추가] ImageIO 객체 사용 : 이미지객체

'웹_프론트_백엔드 > JAVA프레임윅기반_풀스택' 카테고리의 다른 글
| 2020.04.03 (0) | 2020.04.03 |
|---|---|
| 2020.04.02 (0) | 2020.04.02 |
| 2020.03.31 (0) | 2020.03.31 |
| 2020.03.30 (0) | 2020.03.30 |
| 2020.03.27 (0) | 2020.03.27 |



